
Blog
How Teamlocus uses machine learning to extract text from images, documents, videos, audios, etc?
Understanding Amazon Rekognition
Amazon Rekognition is a reliable, highly scalable solution for image recognition that detects objects, scenes, identifies celebrities and faces, extracts text, and helps in the identification of offensive content in photographs. To cater to person counting and public safety use cases, Amazon Rekognition also offers highly accurate facial recognition and facial search features that you can use to evaluate, identify and compare faces.
Features of Amazon Rekognition
-
Labels
Amazon Rekognition helps in the identification of thousands of objects like cars, buildings, mobile phones etc. Along with objects, it also identifies various scenes such as the scene of a city or a beach. In the case of analyzing a video, it can also identify specific activities like “driving a car” or “drinking water.”
-
Custom labels
This feature would help you to extract information from videos or images that are uniquely helpful to your business. For example, you can find your logo on social media platforms, identify your products in grocery stores or look for your animated characters in videos.
-
Text detection
Text may appear differently in photos and videos. But, Amazon Rekognition cannot just find but also read skewed and distorted text to capture information like names of the stores, forced narratives overlaid on media, street signs, license plate and text on the packaging.
-
Face Comparison
Amazon Rekognition lets you measure the likelihood that is, the faces in two images are of the same person or not. By using the similarity score in Rekognition, you will verify a user against a reference photo in near real-time (AWS).
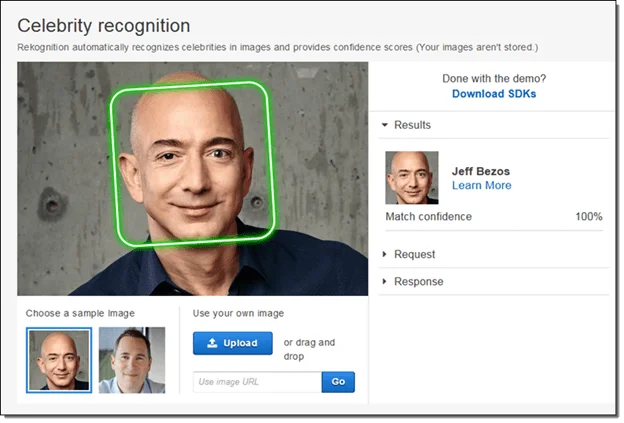
Understanding Amazon Textract
Amazon Textract is a highly controlled machine learning solution that automatically extracts written text, handwriting, and other data from scanned documents to recognize, understand and extract data from forms and tables that are beyond simple optical character recognition (OCR). Companies usually opt for manual data entry or use the basic OCR software which is slow, expensive and is prone to errors. With the use of machine learning, Textract instantly reads and processes all types of documents and accurately extracts data without any manual effort or custom code. Textract is not just efficient but is quick too. It helps you process millions of pages in a few hours.
Features of Amazon Textract
-
Optical Character Recognition (OCR)
Amazon Textract uses the technology of Optical Character Recognition (OCR) that automatically detects written text, handwriting, and figures in a scanned document, such as a legal document or the scan of a book.
-
Form Extraction
Amazon Textract helps you to automatically detect key-value pairs in document images so you can maintain the document’s intrinsic meaning without any manual interference. A collection of connected data objects is a key-value pair. For example, on a document, the field “First Name” could be the key and “Max” could be the value. This will make it easier to import the extracted data into a database or to provide it as a variable into an application. In the case of OCR solutions, the relationship between keys and values are lost until hard-coded rules are not written and retained for each form.
-
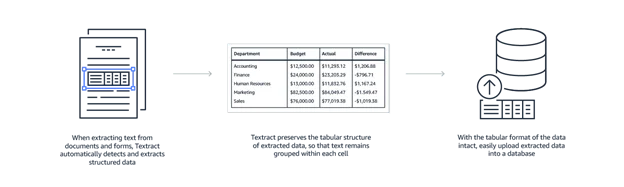
Table Extraction
Amazon Textract offers another outstanding feature that it preserves the composition of data during extraction. This is helpful in case of financial reports or medical records as they are largely composed of structured data. This feature can also be used to automatically load the data that is extracted using certain predefined schema.
-
Handwriting Recognition
With high trusting ratings, Amazon Textract can extract printed text and handwriting from documents written in English, whether it is free-form text or the text is embedded in tables and forms.
It is evident from the above discussion that Amazon Rekognition and Amazon Textract make for useful and helpful tools. The collaborative effort of the two tools stands strong to make a robust document recognition module. This uniquely capable software can be easily used for data identification and extraction from any document such as driving licenses, tax invoices, medical records or other documents.
Amazon Textract and Amazon Rekognition into TeamLocus Search
TeamLocus ability helps you to handle your Alexa TeamLocus tasks such as inserting notes, setting up a meeting, using the calendar or requesting notes from Google. For instance, you click onto a particular image or video from the TeamLocus application and ask Alexa if documents of a particular person naming “Max Harmon” exist? To provide you with appropriate results, TeamLocus would internally use Amazon Rekognition and Amazon Textract to find and extract the data asked for from the available documents. Once the process of searching and extracting is completed, Alexa would return with the required results. By the means of these powerful tools, the lengthy and manual process of searching and extracting information is simplified making it efficient and error-free.
Conclusion
With the use of Amazon Rekognition and Amazon Textract, companies can drastically reduce the time used to populate the required fields of a document from 1-2 minutes to 5-10 seconds. These tools excel the process in terms of accuracy and time making document recognition and data extraction easy, helping companies to skip the need for the next step of cross-verifying and editing incorrect fields.